On January 4th, 2021, I started my new job. A year ago I would not have guessed that my next position would take me to a new continent and a new language! This post explains how my wife and I decided to move north to Paris, France from our home in the Western Cape of South Africa.
I would start by discussing the “push and pull” of my employment at the close of 2020. As I wrote in my prior post, my five-year contract at Stellenbosch U could not be renewed due to financial constraints at the university and national level. Other universities in South Africa were interested in bringing me aboard, but none of them had a pot of money ready to fund that effort. If I wanted full-time employment in academia, I needed to show some creativity in finding the opportunity.
Thinking outside the box
In mid-2020, I encountered a Twitter post from the Institut Pasteur in Paris, France. The Mass Spectrometry for Biology Unit sought to hire a research engineer in bioinformatics. I found myself hoping that a team planning to build their bioinformatics through a staff hire might also welcome a senior partner who could help introduce the peculiarities of mass spectrometry. I asked my wife if she would consider living in Europe for a bit, and her adventurous spirit rendered an immediate “yes.” I wrote a cover letter to Julia Chamot-Rooke, the head of the MSBio laboratory since 2012, asking whether I might serve as a “visiting scientist” with her team for a period of a year. Happily, she replied quickly that her team was interested.
It took longer to elaborate the “how” once we had established mutual interest. I would have liked to arrange this as a “sabbatical,” suggesting that I was on leave from Stellenbosch University in order to acquire new skills that I could introduce to Stellenbosch U upon my return. With my contract expiring, though, there was no indication that funding would exist to allow my return to SUN in 2022. We next thought that I might be a “visiting scientist,” but it appears that funds to support these academic exchanges are no longer available within Pasteur. In the end, we opted for a “chargé de recherche expert” title, which is essentially to say that I will be a post-doctoral researcher (with eighteen years of experience since my 2003 Ph.D.). My goal was to achieve a salary that would cover the rent (Paris is pricey), and Dr. Chamot-Rooke was able to exceed that goal.
Indulge me for just a moment to ask a question that makes me tense: “am I still a professor?” In 2005, I became an Assistant Professor at an excellent university in Tennessee, and in 2011, I was tenured and promoted to Associate Professor. In 2015, I became a “full” Professor in joining the Faculty of Medicine and Health Sciences at Stellenbosch. In 2021, have I effectively “restarted the clock” to become a post-doc? It would be wrong for me to claim that I am a Professor at l’Institut Pasteur. I suspect I will use the phrase “visiting scientist” regularly, to reflect that this is a short (twelve month) appointment. I believe I can still use the title “Professor,” but that flows through Stellenbosch University, not Pasteur Institute.
To grow is to accept new challenges
We often think of our careers as a steady rise in the titles we achieve. I was a graduate student, then a doctoral candidate, then a post-doctoral fellow, then an assistant professor, etc. I would argue that times like today’s COVID-19 pandemic will look like an asterisk on everybody’s curriculum vitae. All of us are struggling to teach or to learn, and all of us find that words flow from our keyboards more disjointedly than ever before (note my nearly nine-month hiatus in writing new blog posts!). I could “retire” from Stellenbosch and work on a book idea or two; really I long for that kind of rest! Instead, I feel the best way to grow in 2021 is to take on new challenges that will make me a better researcher / healthier person / caring husband / etc. What are the types of growth that I hope to achieve from my time at Pasteur?
Almost all of my first- or last-author publications from the last twenty years have emphasized “shotgun” or “bottom-up” liquid chromatography-tandem mass spectrometry (LC-MS/MS) data from complex mixtures of peptides. Over that period, the field has absorbed many researchers from other areas, and a bottom-up proteomics user can choose from a substantial collection of well-developed software workflows for developing information from their experimental data. “Top-down” proteomics technologies do not make use of proteases to chop proteins into peptides prior to mass spectrometry. These methods have been developing alongside bottom-up methods, but the number and diversity of software tools to handle identification of such spectra and manage the statistical issues of these matches have lagged behind the bottom-up world. I believe that I will be able to make a valuable contribution by crafting a manuscript of technology assessment for top-down proteomics, asking questions such as “if different top-down instruments analyze aliquots of the same sample, how much do the data overlap?” or “If different software tools are used to analyze the same data files, how much do their identifications overlap?” Having written several papers on repeatability, reproducibility, and quality control, I see many opportunities in the top-down space.
Give back to a country that contributed to my early growth
I was a Sturgis Fellow at the University of Arkansas during 1992-1996, and I was presented with the opportunity to work with Jean-Jacques Madjar, Jean-Jacques Diaz, and Thierry Massé at the University of Lyon during 1994. Those researchers invested in me, but I feel disappointed in what I was able to give them in return. I was deeply uncomfortable working on the “bench,” and I neglected to arrange the proper type of visa to allow me to develop my project more than a couple of months. Frankly, I was so inflexible and shell-shocked at being away from the United States that I’m just embarrassed at how I managed myself. I have always wanted to do better for France, and this year will give me the chance to do that.
Dave in Lyon during 1994
Develop skills in the French language that will let me reach a broader audience
My French skills were developed through two years in high school and two years at university. At one time, I considered adding a minor in French to my degree program. I think that after a year in France, I should be able to carry out a basic conversation without becoming lost. My “stretch” goal, though, is that I would be able to teach bioinformatics in French. If I can reach that level, I could help introduce bioinformatics to students in Cameroon, Tunisia, Morocco, or the Ivory Coast, among others. We know that people who initially speak a language other than English are at a disadvantage in science careers; I would like to make science careers more accessible to francophone students in Africa.
Where might you find French speakers in Africa? Many places!
Lose my COVID-19 belly
Like many people, I gained a lot of weight during the “lock-downs” against COVID-19. I was still putting food in, but I wasn’t expending energy by walking from one campus building to another or wandering around a shopping mall. My wife and I have decided that we will forgo driving a car during 2021. Unlike transportation in the outskirts of Cape Town, public transit in Paris is very well-developed (metro / busses / trains). I know that I will benefit from “hoofing it” home with a backpack full of groceries.
Explore Europe
I love travelling (unlike my younger self), and I hope that we will find some holiday time to visit other major sites in and around Europe. To see Rome again, visit friends in Denmark or Germany or the U.K., or perhaps even fly to Iceland would be much more difficult if we were starting our trips from South Africa.
I am typing these words at Paris in the first week of the new year. May 2021 be an adventure worth remembering!
I started this blog to explain my decision to leave the United States and to move to South Africa. Now it is time for me to say a fond farewell to Stellenbosch University, my academic home for these “fantastic five years.”
I want to thank the people who made it possible for me to come to Stellenbosch U. The South African Medical Research Council teamed with the Department of Science and Technology (now the Department of Science and Innovation) to contribute 60% of the funds required for my five year contract, and the Dean of the Faculty of Medicine and Health Sciences agreed to contribute the other 40%. Gerhard Walzl, now the head of the Department of Biomedical Sciences at the Faculty, marshalled these resources to make my coming possible. After I arrived, he had the challenges of managing me, too!
Gerhard Walzl is the reason I came to South Africa.
You might ask why this contract must come to an end. The reality is that money is very tight in South Africa. Business growth was barely keeping pace with population growth when I arrived, with continuing “load shedding” power cuts undermining the economy. In a recent audit of government spending, only 100 of 421 government bodies achieved “clean” audits; money that should have been invested in national infrastructure was spent in dubious ways. South Africa engaged in a largely successful response to COVID-19, but there’s no question that lockdowns had punitive effects on its economy. In academia, researchers who were able to cover much of their salaries through grants had far more job-security than those who were not (and I have definitely not prioritized grant writing while at Stellenbosch). The academic job market at the close of 2020 is a tough one.
I will write another post about my plans for 2021, but this post is intended to look back at my time with Stellenbosch. Is it all celebrations, or do I have regrets?
From Strength to Strength
Quality Colleagues
I have repeatedly been inspired by the researchers with whom I have worked at my three main universities. I would particularly single out the “SARChi” Research Chairs at Stellenbosch University, the University of Cape Town, and the University of the Western Cape. South Africa designed an incentive funding program to retain South Africans in-country who might otherwise have moved to nations with more developed economies. I haven’t met a “SARChi” whom I didn’t admire.
Ashwil Klein (at right) has infectious enthusiasm!
I would also say that the junior investigators at Stellenbosch and elsewhere are a strong group, too. At UWC I would highlight Bronwyn Kirby and Ashwil Klein; Dr. Kirby “rolled out the red carpet” for me to teach essentially whatever topics I would like, while Dr. Klein always has a new idea for building the use of mass spectrometry at his institution. I will really miss the Immunology crew and the crop of up-and-coming post-docs in Human Genetics and TB Genomics. The wealth of skill in my colleagues throughout the Cape Town metro was always a source of inspiration for me.
The SUN Immunology team in late 2018
Teaching the World
Upon arrival in Cape Town, I was unsure who my students would be. I knew that coursework figured heavily in the “B.Sc. Honours” year, but M.Sc. and Ph.D. students did not typically attend classes. For someone who loves being in front of a class room, it was hard to hear that I would have just a few lectures each year. That said, I’ve offered a variety of courses to all comers, from the week of bioinformatics each year in honours to a once-a-week program to teach the Python programming language. When my program officer with the SA Medical Research Council told me she wanted me teaching as broadly as possible, though, I began talking with postgraduate programs at UWC and (Stellenbosch rival) University of Cape Town about teaching opportunities. UWC, as I mentioned above, has had an endless appetite for classes; in 2019 and 2020, I was teaching a week of bioinformatics, three lectures for sequencing informatics in their Next-Generation Sequencing module, two or three lectures in the Proteomics module, and almost all of the Clinical Biomarkers module! While working with Nelson Soares at UCT (he has since moved to the University of Sharjah in the UAE) I enjoyed our monthly “big show” for the community proteomics meetings, and I gave occasional lectures to their honours program, too.
During his time at UCT, Nelson Soares (right) was very important in building community among Western Cape mass spectrometrists.
One of the happy accidents of such broad teaching was that I was able to record instructional videos of almost all of these classes. Last year I assembled an index to the YouTube videos and slide PDFs that regularly draws more page views than all my other blog entries put together. I have been grateful to present workshops in other African countries from this exposure. So far I have taught in Ghana, Malawi, and Namibia, but I fervently hope to arrange workshops in Ethiopia, Mozambique, Botswana, or… well, practically anywhere!
We mustered forty-nine faces on the final day of the workshop!
This section would not be complete without my praising the students who have chosen my lab for their B.Sc. Honours, M.Sc., or Ph.D. programs. Again, while some of these postgraduate students were at Stellenbosch U, I also served as co-supervisor to students at other universities, even a pair of M.Sc. students at the U of Malawi College of Medicine in Blantyre! Just like the best students I knew back in the States, these postgraduates frequently pushed me to learn new techniques and application areas; to give one example, a 2020 UWC B.Sc. Honours student wanted to work in GI disease, so we framed a challenging project in celiac disease, a first time for me as well. She did an amazing job with it! Just a couple weeks ago, I attended the Ph.D. graudation ceremony for Marina Kriek, a researcher who joined my team after working in industry. I am very grateful for the chance to work with such talented individuals.
Linking South Africa into Global Networks of Molecular Biology
South Africa is a very cosmopolitan place, with postgraduates frequently accepting jobs in Europe or America. Many of the professors who rise to high leadership positions have experience working at institutions in the Global North. My experience with global mass spectrometry, however, had left me something of a blind spot for proteomics research within South Africa. I would highlight two different projects during my time with Stellenbosch that I hope will increase the awareness of what South Africa has to offer on the global stage. After living in South Africa for two years, I had gotten to know researchers at mass spectrometry laboratories across the country. At the invitation of Ron Orlando, a team of us crafted a manuscript describing the types of challenges associated with establishing mass spectrometry facilities in the developing world. Writing a paper with colleagues from six different institutions was challenging, but I was delighted with the result. Our product was later selected as the paper of the year for the Journal of Biomolecular Techniques (the journal of the ABRF)!
HUPO-PSI 2019 drew together friends from near and far!
In 2019, we were able to make another stride forward into the international community when the Human Proteomics Organization (HUPO) Proteomics Standards Initiative (PSI) held its annual workshop in Cape Town. At first, I was unsure how many of my colleagues would make the trip to the southern tip of Africa, but our attendance was really solid, and many South African graduate students got to network with leaders in the field of proteome informatics. Since this was the first science meeting I had ever organized, I was thrilled with the result.
Emerging Research Interests
Scientists, like all people, can fall into a rut if undisturbed. I have spent the great majority of my career publishing on the identification of peptides, proteins, and post-translational modifications from tandem mass spectrometry data. It’s been a lovely “rut!” Coming to South Africa, however, meant that I would need to broaden my thinking to handle a broader array of bioinformatic and biostatistical challenges. Could I help people accustomed to manual interrogation of flow cytometry data begin using more automated techniques for gating? Could I automate recognizing DNA sequence variants through high-resolution melt curves? While I made some starts in these two directions, the challenge that has been consuming most of my concentration recently has been this: how can we conduct “functional genomics” (transcriptomics or proteomics) in non-model organisms without well-established genome annotations? After substantial work in Salvia hispanica (chia), Crocuta crocuta (spotted hyena), and Hermetia illucens (black soldier fly), I finally feel I have enough answers to pen manuscripts. I have enjoyed asking myself again just what I find interesting!
Pangs of Remorse
Just as there are no perfect people, there are no perfect jobs! I have plenty of reasons to have enjoyed the last five years, and I hope I’ve been able to convey that above. I have, however, experienced a couple of sticky points that have bedeviled me.
Shaken to the Core
Because my professorship was primarily funded from external sources, I was named as a “Research Chair in Proteomics” for Stellenbosch University. I interpreted that title as making me responsible for seeing proteomics technologies deployed as adeptly and as broadly as possible. I sought to establish a solid relationship with the Central Analytical Facilities, which operated the Proteomics Laboratory of the Mass Spectrometry Unit at the Faculty of Medicine and Health Sciences. Seeing that the Proteomics Lab relied on several external USB hard drives as backups, I built a file server for their exclusive use from one of the heavy servers I had brought with me from the States. I offered my services to help researchers who had produced data in the Proteomics Lab get the most information possible from those experiments. For those first few months, I felt we were well-positioned to see real growth in mass spec-based proteomics.
I had become aware, though, of some challenges that caused some potential mass spectrometry users to walk away from the Proteomics Lab after initial pilot experiments. These challenges were not unusual ones for core facilities. They related to reproducibility and comparability, prices for services, experimental sensitivity, etc. I briefly spoke with the head of Central Analytical Facilities at an impromptu meeting, and he recommended that I put my suggestions for how CAF Proteomics could be improved in writing. Halfway into 2016, I wrote a four-page letter detailing ways that my division could work with the Proteomics Lab to improve “takeup” of proteomics at our university. Well, my relationship with CAF immediately cratered. To give a very concrete example, my Proteomics Laboratory key was reclaimed the very next day. I was the Research Chair for Proteomics, but after the mid-point of 2016, my ability to work with the Proteomics Laboratory at my own campus was at an end. I never really recovered from this loss.
No Job is Finished…
Sharing an office with three other staff
Something I hadn’t truly appreciated about my previous institution (an excellent university in the state of Tennessee) was the degree of staff support we enjoyed. As an assistant professor there, I and a handful of other professors were supported by an administrative assistant. When I wanted to write a grant, our department had its own grant coordinator. Even as a new assistant professor, I had my own individual office, with space adjoining it for my lab team. It is important to understand that a grant awarded to a professor is split into “direct costs” (monies to fund the research directly) and “indirect costs” (monies to keep the lights on). At my former institution, an NIH grant of a million dollars would be accompanied by indirect costs of $600,000, reflecting an “facility and administrative rate” of 60%.
I loved my individual office when it was ready!
NIH grants are frequently won by professors at Stellenbosch University, but their “facility and administrative rate” is locked at 8% because we are not an American university. As a consequence, departments at Stellenbosch are much less able to support a large number administrative staff. A large load then falls on individual staffers for handling issues such as travel reimbursement and shared equipment loan (such as the tabletop projector for the seminar room). I would particularly like to mention Trudy Snyders, the senior secretary for our division, who demonstrated great patience with me on many occasions. The Faculty of Medicine and Health Sciences does have a Research Grants Management office, but a substantial amount of grant proposal help within our division came from the generosity of Helena Kuivaniemi, a professor with unflagging energy. Until the final year of my contract with Stellenbosch, our division occupied two floors of the aging physiology and anatomy (Fisan) building, with space at such a premium that even some SARChi Chairs were sharing a room with other lab heads. At the conclusion of 2020, I was able to see my division happily taking up residence in the new Biomedical Research Institute, a huge upgrade in its infrastructure.
All in all…
I was very lucky to have these five years with Stellenbosch as a time to reinvent myself. Living in these beautiful surroundings, working with people I admire, allowing me to tinker with new possible directions for my research was a genuine gift. Some cynics back in 2015 told me I would regret moving myself across the Atlantic, but I wouldn’t give up this time for anything. Stellenbosch has made its mark on me.
Since flu season can last until May in the Northern Hemisphere, a person appearing in the emergency department with nonstop coughing and labored breathing could represent influenza or COVID-19. Given that we have now confirmed that more than 100,000 people have a case of COVID-19, it is clear that we need clinical tests to find the people carrying the SARS-CoV-2 virus (you may also see the name “2019-nCoV” used). This blog post is intended to explain the “real time reverse-transcription polymerase chain reaction” used to confirm that SARS-CoV-2 has infected a patient.
Johns Hopkins keeps us abreast of the current status of the outbreak.
As a starting point, I would note that real time RT-PCR is a mainstay in humanity’s battle against coronaviruses. In 2003, a team at University of Hong Kong published an optimized method of this type for recognizing the earlier SARS virus. Since the 2019 SARS-CoV-2 virus is a close relative of SARS-CoV-1, it makes sense that we would adapt the tools from our earlier epidemic to the current one.
How real time RT-PCR works
In my earlier post, I noted that the genome of the SARS-CoV-2 virus is a positive-sense single-stranded RNA. To use a technical term, RNA is twitchy; if a newcomer tries to work with it in the lab, we frequently find that the molecule degrades due to pH changes or RNAse enzymes that chop it up. One of our first moves, then, is to make a DNA molecule that is the complement (opposite strand) of the virus RNA genome. This requires an RNA-dependent DNA polymerase (also called a “reverse transcriptase”), an enzyme used by retroviruses like HIV to manufacture DNA from an RNA template. Making cDNA from the RNA in a sample makes a stable copy for what comes next.
Polymerase Chain Reaction (“PCR”) is a technique that is absolutely indispensable to modern molecular biology. Ideally, each cycle of PCR doubles the number of copies of a targeted piece of DNA. Even if one is starting with a modest number of DNA molecules, a few cycles can boost those numbers considerably. Ten cycles at perfect efficiency, for example, should “amplify” each starting molecule into 1024 copies. One of the protocols created in Germany to detect SARS-CoV-2 allows for up to 45 cycles of PCR, meaning each starting molecule would become 35,184,372,088,832 copies (again, assuming perfect efficiency)! Amplifying with PCR is essential in the clinical test because we need enough copies of the genome to be able to detect them.
The last aspect I want to explain is the first part of the name, “real time.” In the bad old days, researchers would radioactively label probe DNA to determine whether or not it had annealed in a particular spot. If photographic film became dark in that spot after a long exposure, we knew that that our probe DNA annealed. We are much happier today that we can use fluorescent reporter dyes for instant feedback. Ideally, we want a fluorescent system in place that will tell us how many copies of our target DNA are present in the sample so that this is a quantitative assay (Often you will see this written as “qRT-PCR” to reflect that goal). We check fluorescence after every cycle of PCR. When we detect a sure fluorescence signal (one higher than a pre-specified threshold), we write down the cycle number as the “Ct” value for this sample.
Fluorescence measurements for each cycle of a PCR amplification via Wikimedia Commons
It’s all about the primers
Since real time RT-PCR is such an established method for virus screening, one might wonder why many patients in the United States have found it difficult to get themselves tested. The journal Science and the Washington Post have both recently published on the mistakes that prevented the Centers for Disease Control and Prevention from mass-producing a test for use throughout the United States. For the U.S., the usual sequence of events for a new disease test looks like this:
Typically, there are few confirmed viral samples from patients at the outset, which researchers need to validate their tests, and CDC has the capability to grow the virus for this critical quality assurance step. Once the agency has a working test, that goes out to state labs. Then, in a third phase, commercial labs take over and either produce their own tests or scale-up the CDC one.
China developed an qRT-PCR test at a very early stage, publishing their test on January 21, 2020. Germany was also out of the gate early, publishing their test on January 17, 2020 (their approach was adopted by the World Health Organization). The CDC’s own test was made public on January 24, 2020. If you are interested, you can even review the step-by-step directions for conducting the test. I was proud of my alma matter, the University of Washington, for creating their own assay to detect this virus because of the outbreak in the city of Seattle.
A diagram showing the primers used in the German test for SARS-CoV-2
These assays all use different primers, the DNA guides that specify which pieces of DNA are amplified in PCR. The primers need to be designed to match parts of the viral genome that are conserved (unchanging among all circulating viruses). The sequence chosen for the primer is also important because it must be very specific to the virus to be detected. If the primers were picked for an area that is common to all coronaviruses, we could determine that one of these viruses were present (SARS-CoV-1, SARS-CoV-2, or MERS-CoV) but not which one is present.
If primers are chosen inconsistently, it is possible that a sample could appear positive on one test (because its viral sequence matched the test 1 primers) while appearing negative on another test (because its viral sequence did not match the test 2 primers). Naturally, we’d like all the tests for COVID-19 to agree perfectly. At present, NCBI Virus shows 108 different virus sequences for SARS-CoV-2. The China National Center for Bioinformation, on the other hand, has released 380 virus genome sequences! Our ability to discern good places and poor places to align our primers is getting better with each new sequence.
Putting the tests to work
From what I’ve written above, it would seem that the CDC was ready to start wide screening for SARS-CoV-2 in late January. Two big barriers, however, stood in the way.
First, when CDC released the test for use in state laboratories on February 5th, several of the laboratories reported getting a positive result on the negative control that was distributed with the test. Naturally, we want to avoid two types of error with any clinical test: we do not want to claim healthy people are sick, and we do not want to claim sick people are healthy. We include negative controls in our COVID-19 tests so that samples known to lack the virus are tested alongside “unknowns.” If we see a positive result for a control known to lack the virus, something is wrong with the test. Multiple states reported that the tests they received from the CDC produced positive results for the negative control. As a result, they were allowed only to forward their samples to CDC for centralized testing.
This image from the February 1, 2020 version of the CDC’s Health Alert Network restricted testing to too small a population. It has been superseded by two later revisions to this policy, at the time of writing.
The second chief problem came from CDC’s guidance on who could be tested for the virus behind COVID-19. Only patients who had recently traveled to Mainland China or who had been exposed to a person known to have been infected by the virus could be tested. As a result, we neglected to test people we later realized were carrying the virus to others in the community. As of this writing, the guidance on testing has been expanded:
Priorities for testing may include: 1) Hospitalized patients who have signs and symptoms compatible with COVID-19 in order to inform decisions related to infection control. 2) Other symptomatic individuals such as, older adults (age ≥ 65 years) and individuals with chronic medical conditions and/or an immunocompromised state that may put them at higher risk for poor outcomes (e.g., diabetes, heart disease, receiving immunosuppressive medications, chronic lung disease, chronic kidney disease). 3) Any persons including healthcare personnel, who within 14 days of symptom onset had close contact with a suspect or laboratory-confirmedCOVID-19 patient, or who have a history of travel from affected geographic areas within 14 days of their symptom onset.
A look at the current map of worldwide COVID-19 cases is haunting. More than 4000 people have died, and 114,000 people have been diagnosed with the disease (and those numbers will be out of date by the time you read this). The most recent situation report from the WHO, however, shows some really good news that I want to highlight (numbers come from report 49):
As the nation where this virus was first observed, China has borne the brunt of COVID-19 disease, with more than 3000 of the deaths taking place there. It may surprise you to learn that China diagnosed only 105 people with the disease in the last 24 hours (45 confirmed, 60 suspected). During that same period, an additional 23 people died of COVID-19. These losses are tragic, but they also represent a huge drop versus what China was facing on Valentine’s Day. This epidemic can be beaten, and the measures China has taken have been effective.
The Republic of Korea has a different governmental system than China, of course, and that made some differences in what policies could be used to limit spread of the disease. Korea opted to make widespread testing its mechanism to ensure that people with the virus spread it no further. They even created “drive-through” testing centers (an idea later adopted at the University of Washington). Their surveillance was able to detect cases as soon as possible, cutting into the hidden transmission of the virus. In Situation Report 49, we see that Korea has diagnosed a total of 7382 cases of COVID-19, with only 248 added in the last 24 hours. They are beating this disease because they are screening for it.
As countries all over the world are detecting the arrival of COVID-19 on their shores or are detecting growing numbers of cases each day, it is worth remembering that public health officials are doing their best to get ahead of this virus. We have many miles left to go, but I imagine that two or three months from now, the initial panic will have given way to determination. We will drive the new infection rate for SARS-CoV-2 to zero!
In 1841, a ship docking at Alexandria unleashed a panzootic with dire consequences for Africa (a panzootic is the equivalent of pandemic, but for animals). Within two years, 665,000 cattle had died throughout Egypt [Cattle Plague Chapter 22]. Much worse was yet to come, though. During 1888-1896, the “rinderpest” plague blasted from the horn of Africa all the way South to the Cape Colony and all the way West to Senegal. The rinderpest caused over 90% mortality in the previously flourishing cattle populations of Africa. Wild herds of buffalo and wildebeests also suffered tremendous losses, sometimes acting as disease carriers between distant kraals of cattle.
This image from the AVIS consortium relates the symptoms of rinderpest.
Cattle have long held great socioeconomic significance in the traditional pastoral societies of Africa. Cattle’s role in these societies is not simply one of economics and survival because cattle play a key role in ritual and social definition. A person’s wealth and social importance could be shown in the size of herds; a man’s ability to accumulate and loan cattle defines the role he plays within his community. Even the spatial layout of villages is defined by cattle/male spaces and non-cattle/female spaces. The central kraal is where male elders would conduct their work. Cattle meat is exclusively reserved for the consumption of chiefs and for ritual practice. Dairy products, however, are a key part of the agro-pastoralist diet. Cow milk and blood from living animals may be mixed with millet to create a nutritious porridge. The fermentation of milk to produce amasi is commonplace. Cattle knit society together; for a leader to entrust part of the herd to a follower’s care could represent a statement of alliance. In some cultures, a young man cannot marry until he has acquired cattle. Wars have been initiated by ceremonially stealing a single animal from another group (such as the 1863 ovita vyongombongange described in Wallace, p.63). The great rinderpest plague destroyed far more than a food source; it undermined the fabric of traditional societies across Africa.
A general diagram of the central cattle pattern from Badenhorst (2009).
In 2011, the rinderpest virus was announced to be eradicated in the wild, only the second virus to reach this status (after smallpox in 1979). Today, laboratories that still house samples of this virus are being urged to “sequence and destroy” them to prevent their ever escaping into the wild. In this post, I’d like to detail the rinderpest virus and describe how we eradicated this threat.
Rinderpest is an example of the morbillivirus genus within family Paramyxoviridae. This genus harbors some genuine killers. The one everybody cares about is rubeola, the virus that causes measles. Rubeola is one of the most contagious viruses in the world for person-to-person transmission, as summarized in the “R naught” metric of 12 or higher (rinderpest scores 4.6 on this scale). Until recently, almost every child was vaccinated against rubeola infection, typically in the “Measles Mumps Rubella (MMR)” vaccine. This vaccine definitely counts as one of the miracles of modern medicine, so I am frankly irritated that people make up nonsense to suggest that ordinary children should not receive this vaccine. Save a life, perhaps your own child’s, by ensuring your kids are vaccinated.
Superficially, paramyxoviridae such as rinderpest seem quite similar to the SARS-CoV-2 virus that causes COVID-19. Both are enveloped viruses of around 150 nm diameter that contain a single-stranded copy of the genome in RNA. Rinderpest, though, has a “negative sense” genome rather than the “positive sense” genome of SARS-CoV-2. The rinderpest genome is only about half the size, at 15.88 kb (thousands of nucleotide bases). The set of genes for paramyxoviridae is pretty different from those of SARS-CoV-2. Here’s how the changes play out:
The grappling hook: Hemagglutinin, made famous by the influenza virus, is one of those proteins that makes me think “sinister!” Our cells frequently use sugar molecules on their exteriors as doorbells of a sort. Hemagglutinin attaches to sialic acid, triggering the cell to engulf the virus. While it’s ringing the doorbell, the Fusion protein causes the viral envelope and cell membrane to merge so that the viral contents can enter the cell. Nasty.
The production line: Negative-stranded RNA viruses need to send messenger-RNA to the cell’s ribosomes to produce viral proteins. It cannot use the cell’s transcription machinery to do that, though, so it must contribute its own RNA-dependent transcription equipment. We think of the Central Dogma of molecular biology allowing mRNA to be built from a dsDNA template, but viruses don’t really care about our “rulebook.”
The genome copier: Every virus wants to manufacture more viruses once it has sufficient control of cellular machinery. The same enzyme that built the transcripts for individual genes of the virus can switch to another mode that creates a complementary copy of the virus genome. “Not so fast,” you say, “the complement of a negative sense viral genome is a positive sense strand. You can’t ship that out and get a functional virus!” Here’s the tricky part: once the RNA-dependent RNA polymerase has made a full-length positive-sense complement to the genome (“antigenome”), it can build a complementary strand to the positive-sense genomic RNA that will then be a negative-sense genomic RNA, ready for packaging. One gene is capable of making 1) mRNAs from the viral genome, 2) full-length complementary RNA genome copies, and 3) a full-length negative-sense RNA genome ready for viral packaging. The virus has placed our Central Dogma in the trash and closed the lid!
How we beat the rinderpest
(1896, probably near Vryburg) Eradication teams slaughtered all livestock in areas expecting arrival of the rinderpest virus.
Initial efforts to prevent the spread of rinderpest into South Africa were reminiscent of zombie movies. A pair of massive fences along the border with Botswana was intended to prevent infected cattle from wandering from Matabele lands. The area near Mafeking was proclaimed a “cattle-free zone,” and many herds were shot and buried. Despite these efforts, rinderpest repeatedly appeared within South Africa. Any herd with a single infection reported was immediately slaughtered. Thousands of animals were destroyed to forestall the spread of the disease, but eventually a transport rider brought the disease to the Eastern Cape. An estimated 2.5 million cattle died in Southern Africa between 1896 and 1899.
The agro-pastoral communities understandably did not have a lot of trust for the white settlers’ claims about the best way to manage the spreading plague. The people of these communities didn’t generally appreciate the disinfection of their persons, particularly when it was used as retribution rather than a clinical necessity. The destruction of a cattle herd was eviscerating to people living in traditional communities in a way that it was not for white farmers. At a high level, the relationships among leaders were destroyed when the cattle that represented those links were dead. At the ground level, people were forced to eat “roots, grubs, locusts, and even decaying meat” to survive. Rinderpest played an out-of-scale role in the destruction of traditional society throughout sub-Saharan Africa, just as the Scramble for Africa was reaching full steam.
Local researchers Dr. Arnold Theiler and Dr. Herbert Watkins-Pitchford banded together to fight rinderpest, but the government wasted their time by compelling them to test the spurious “remedies” put forward by farmers such as water deprivation and snake venom. European expertise was recruited at substantial expense. German Scientist Dr. Robert Koch resided in Kimberley from 1886 to 1897 working this problem, and a team of French scientists from the Pasteur Institute came to South Africa near the end of Koch’s period in country.
Dr. Koch, already famous for his work in anthrax and in enunciating “Koch’s Posulates,” arrived with considerable star-power. He brought Dr. Paul M.J. Kohlstock to assist him. Koch was initially skeptical of Russian Professor Eugene Semmer‘s findings that fluids removed from infected animals could evoke a protective response if injected into an animal that had not yet developed illness. When Koch announced in February, 1897 a treatment based on this strategy, using 5 mL of bile from sick animals, he was celebrated as a hero. Kohlstock accepted an invitation to German Southwest Africa (the colony that later became Namibia) to introduce a refined technique there.
Robert Koch was widely considered a great man by the time of this 1897 photograph from the Wellcome Collection.
In practice, the Koch “Bile Method” was nearly as problematic as the absence of a cure. The death rate of treated cattle was approximately half; the protective benefits only began days after treatment and lasted less than half a year. In German Southwest Africa, some indigenous farmers objected when they saw that cows were repeatedly taken from their farms for bile production to save cattle at other farms (this process was, of course, painfully fatal for the cow). The French team of Mr. Jean Danysz and Dr. Jules Bordet built upon experiments by Theiler and Watkins-Pitchford to develop the “Serum Method,” which soon bore the moniker the “French Method.” It was announced just six months after the Bile Method and soon came to supplant it. When war was declared at the start of the Second Anglo-Boer War in 1898, the panzootic was nearly under control within South Africa.
The modern world was not freed of rinderpest by these early strategies. A tissue culture-based vaccine was created by English Research Veterinarian Walter Plowright at Kenya in 1960. I feel a sense of kinship with him because he also left his homeland to join in the amazing story of Africa! His vaccine was applied aggressively in cattle throughout Africa by Joint Project 15 project to reduce the rinderpest pockets to just the Niger Inland Delta and an area of southern Sudan. A renewed effort by the Pan-African Rinderpest Campaign in the late 1980s followed another wave of the disease out of these pockets. A 1992 effort created a thermostable vaccine that could be used even if left unrefrigerated for a week!
Stamping out rinderpest took a worldwide effort over decades (from Our World in Data).
As detailed in Mariner et al, rinderpest eradication required much more than just a viable vaccine. Teams of “local intermediaries called community-based animal health care workers” were recruited and trained, though some locals perceived this effort as competition for their jobs. Eradication was not a strictly top-down effort. Instead, community knowledge of herds and migration schedules and made a significant difference in handling local outbreaks quickly. The network created by the PARC effort may be useful in controlling other diseases such as “peste des petits ruminants,” bird flu, Rift Valley fever, and foot and mouth disease.
Rinderpest posed a tremendous challenge to African communities in the late nineteenth century, but the rapidly evolving field of veterinary medicine was able to control it long enough that it could be eradicated by modern techniques. When the chips are down, it’s a good idea to have some scientists on call!
[I want to offer a special thank you to Natasha for helping me understand the importance of cattle in indigenous societies.]
As the world learned that the USA had assassinated Qasem Soleimani during the first week of 2020, doctors in China were coming to grips with a new viral infection that was spreading rapidly through the population of Wuhan. Wuhan is the capital of Hubei province, with a metro population above 19 million. Coincidentally, I had visited Hangzhou, China (800 km / 500 miles distant) just two months before!
The first hospitalization of a patient diagnosed with the COVID-19 disease took place on December 12th, 2019. The initial spread apparently took place in the Huanan Seafood Market, a “wet market” in the city. As the severity of the new virus became apparent, the market was closed on January 1, 2020. These markets generally feature both live animals and meat, and yet Huanan was quite close to the center of the city. The proximity of animals particularly matters in this case, because COVID-19 is a “zoonotic” disease. In other words, this virus didn’t suddenly appear out of nowhere; instead, it is believed to have jumped the species boundary to enter human populations from an animal population. It’s quite possible that the virus jumped from a wildlife population (likely bats, in this case) to a domesticated animal population to humans. This property is not particularly unusual; we frequently see strains of influenza jump from other species, and we believe that HIV derived from Simian Immunodeficiency Virus.
A molecular view of COVID-19
I am stunned to learn how much information has been produced in just two months for COVID-19. The World Health Organization settled on a name for the disease during the last week; it appears that the virus will be called SARS-CoV-2, replacing the temporary name 2019-nCoV. For information about the disease, I suggest a visit to websites for the Centers for Disease Control and Prevention or the World Health Organization. I was also impressed by what I found at the famed journal Lancet. For my part, I was glad to see the volume of molecular information already available at NCBI and particularly the Protein Data Bank. To have seen this virus for the first time only a month and a half ago, scientists have clearly been putting in overtime hours!
At left, T4 bacteriophage by Adenosine at Wikimedia Commons. At right, a SARS coronavirus invades, by David S. Goodsell of RCSB Protein Data Bank.
When people envision the word “virus,” they might think of an icosahedral bacteriophage like the left part of the image above; these complexes of protein and nucleic acid are indeed viruses. Frequently the viruses that infect humans have a rather more complex structure. Coronaviruses like the one that causes COVID-19 are large, enveloped, positive-sense single-stranded RNA genome viruses with a strong penchant for recombination. They have been studied extensively since their discovery in the late 1960s. I’ll try to explain that description here.
Let’s start with “large.” Each coronavirus is fairly bulky, with a size between 80-160 nm. Quite a few of the media stories about the virus show people wearing disposable breath masks. Even the best of those masks are designed to filter particulates of 0.6 microns, or 600 nm; the goal, then, is to block droplets containing the virus rather than individual “naked” virions. When doctors work with nasty respiratory diseases like multiply drug-resistant tuberculosis, they generally wear an N95 respirator. Those are intended to block 95% of particulates of 300 nm size. I was surprised to learn that N95 masks are not as effective for people who wear beards!
The term enveloped is used to describe a virus that is surrounded by a membrane. You can see electron micrograph images of the virus causing COVID-19 at Flickr (including the one at the top of this post). Coronaviruses still contain many proteins and copies of a genome, but they are surrounded by a lipid bilayer, just like human cells. When human cells are hijacked to manufacture many copies of the virus, the mature virions “bud” from the cell surface, surrounding themselves with a bubble of the cell’s own membrane. This membrane is also important in their invasion of new cells. The virus initiates a membrane fusion to merge its envelope with the target cell, releasing the virus contents into the new cell.
To say a virus employs a “positive-sense single-stranded RNA genome” will bewilder most people, so let’s visit each word. Human genomes are made of double-stranded DNA, the familiar “double helix.” Our 23 pairs of chromosomes amount to a total of roughly three billion nucleotides, with just over 20,000 protein-coding genes. Bacterial genomes are also double-stranded DNA, but they are far more compact. Our intestinal friend E. coli, for example, has a genome size of 4.7 million nucleotides (0.15% the size of human genome), coding for around 4,400 protein-coding genes (22% the size of the human proteome, discounting variable splicing etc.). The virus that causes COVID-19 has a genome around 29,900 nucleotides in length (0.64% the size of the E. coli genome). Counting its proteins is a little challenging since many viruses produce “polyproteins” that are translated in one long polypeptide and then cleaved to functional proteins via proteases. Instead of being stored as double-stranded DNA, though, each virus contains the genome in a single RNA molecule that is not base-paired (rather than a twisted ladder, the RNA strand can adopt a complicated shape on its own). We describe it as “positive-sense” because once the RNA genome has been released from the virus, it can immediately be translated by the cell’s ribosomes to produce protein!
We have seen viruses like this before. As of Valentine’s Day, scientists had sequenced 78 different SARS-CoV-2 viruses, giving us a reliable look at its “wild type” sequence. In this case, the name indicates a strong similarity to SARS-CoV, a virus resulting in the SARS outbreak of 2002. COVID-19 appears to spread a bit more easily because people in the earliest stage of the disease are more able to walk around than people in the earliest stages of 2002 SARS.
PDB structure 3DDK is an example of an RNA-Dependent RNA Polymerase from Coxsackievirus.
This virus sequence can change rapidly. One of the reasons cells store their genomes in DNA is that DNA is more resistant to mutation than is RNA. Positive-sense RNA viruses employ RNA-dependent RNA polymerase to manufacture new viral genomes, and this enzyme makes proofreading mistakes in about one of every 10,000 nucleotides added to the sequence. Since the sequence of the viral genome is roughly 30,000 nucleotides in length, that means we expect three “letters” to be wrong every time a new genome copy is made. In addition, coronaviruses are noted for their ability to “mix it up” through recombination, a process where different genomes swap segments. Recombination is a mechanism by which a virus can undergo “antigenic shift,” drawing together the worst of multiple strains in a single virus.
Rhinolophus sinicus, the Chinese horseshoe bat, is common in China and as far west as Nepal.
This virus matches sequences we have seen in bats. The publication announcing the genome sequence of this virus noted a strong similarity with Bat-SL-CoVZC45 and Bat-SL-CoVZXC21. We are fortunate that researchers began looking at coronaviruses in wildlife populations in the aftermath of the SARS outbreak. Those carefully curated sequences, along with the information drawn from SARS-CoV itself, provided a base of information against which the SARS-CoV-2 could be compared including protein crystal structures. As we pursue vaccines and symptom-reducing drugs, this information, particularly concerning the cell surface receptor targeted by the virus, will be crucial in stopping its spread and relieving those who have been infected by SARS-CoV-2.
Protein Data Bank 2AJF shows the SARS coronavirus spike receptor-binding domain complexed with its receptor, ACE2.
An index to this series can be found at the first post.
Zig-zagging southern Kruger Park: December 19, 2019
As this morning dawned, Natasha and I reckoned with relocating ourselves to Skukuza, one of the largest rest camps in Kruger Park. Natasha was fending off a couple challenges at home: we had reports that our security system wasn’t powering up after a battery failure, and recent rainstorms had caused some water damage to our ceiling. It’s difficult fielding those things without any internet services! Satara Rest Camp is too remote from cellular towers to offer any but sporadic mobile internet service, and none of the service offices supply wifi. It’s the most complete network blackout I’ve experienced since my visit to Cuba!
We took the scenic route from Satara to Skukuza. I didn’t enjoy the traffic, though!
Our course to Skukuza was less than direct. We began with the run from Satara to Tshokwane (“Sausage Tree”). This leg was rather pretty, even if we didn’t see huge numbers of new animals. Natasha did capture a really lovely image of a giraffe, one of a trio we came across.
If you count the legs, you’ll see there’s more than one giraffe here.
Soon thereafter we came to Kumana, where we visited the most Southerly Baobab tree in the park. It had the most interesting trunk structure, as though several smaller trees had fused together. Natasha reports the Kumana tree as her favorite. The stop also offered us a nice photo opportunity for the Southern Ground Hornbill, with vivid red-on-black feathers.
This tree is officially the southernmost baobab in Africa, but I suspect saplings can be seen further south!
Later we encountered a Martial Eagle and Bateleur, though they evaded good photos. The bird theme continued at Tshokwane. The starlings seemed to have an iridescent blue cast to their wing feathers that I didn’t recognize from their American cousins.
Natasha was in the mood for an adventure, and she persuaded me to try a triangle route to Skukuza; instead of driving directly there from Tshokwane, we opted to drop south to Lower Sabie Rest Camp along the H10 and then come back up and west to Skukuza Rest Camp. The run south on the H10 was surprising; it began with a hill climb to the high Nkumbe Lookout. From up there, we felt like we could see forever! We watched an elephant hike from one water hole to another, some distance away.
Nkumbe Lookout allows you to see forever.
Since this area is sometimes frequented by rhinos, we kept our eyes peeled, but none made an appearance. We did, however, encounter some rangers working with sniffer dogs. Natasha suspected they were on an anti-poaching mission. We came to a bidirectional pileup of cars when we were west of the Muntshe hill. A guide hollered that their group had found a leopard relaxing in a tree in the distance. It was our second pileup relating to a leopard sighting, and yet we were never entirely sure which tree they meant!
If I were a hippo, I think I would enjoy the Lower Sabie.
The Lower Sabie Camp was nicely sited, and I snapped a few photos of the river’s flow as we crossed. We stopped for an ice cream and then I took over driving for the last leg. The traffic coming out of Lower Sabie was pretty intense, though, and our drive along the H4 to Skukuza was never really solo. We pulled off to the N’watimhiri Causeway to get away from the noise and immediately found some giraffes (Natasha was delighted). We hoped that the neighboring river might contribute some hippos, but we didn’t really hear their calls.
You have a really nice campsite here. It would be a shame if something happened to it!
At Skukuza we were able to check in without a problem. As dinner time arrived, however, a troop of vervet monkeys began running shuttle routes among the braai areas of the tourist rondavels, as though they were looking for who had the best monkey dinners on offer. It was quite the family affair: mommas, poppas, and clutching babies were all over the show. I tried to keep posted near the grill until they had moved to other parts of the housing area to send the message “this grill is protected.” We did as much meal preparation and eating inside our little rondavel as we could!
Veterinary Wildlife Services: December 20, 2019
During the following afternoon, we had an unusual opportunity to visit the Veterinary Wildlife Services at Skukuza (my Stellenbosch University colleague Michele Miller works there). The camp is distinct from the others by more than the number of tourists it can serve. Skukuza, for example, offers a small airport from which the Park Service operates helicopters.
The Veterinary Wildlife Services are not essentially a large animal hospital, however. Instead, research to limit infectious disease and defeat poaching is centralized at this facility. Natasha and I learned quite a lot!
I cannot believe that this is the only photo of Michele that I acquired!
Many of the veterinary services undertaken by the team require that the personnel are airlifted or driven into rough terrain. Working on a fallen animal takes place where it can be found, not at the building. As a result, many of their kits for operating are in tubs or boxes, ready to be dumped into the vehicle at short notice. Michele showed us the new portable radiography equipment and a new portable respirator recently purchased through Stellenbosch University. She also showed us a very secure space to ensure that valuable items and medications are never taken from the facility!
These devices stimulate graduate students after tiring hours of research.
The research lab space seems really solid, as well. Because the site occasionally hosts student researchers, they have a room of bench space. The permanent staff have their own, with equipment such as GeneXpert machines ready to go for tuberculosis detection. The labs also have plenty of “biobank” space in place to store samples of blood, hair, and skin from animals who are part of research studies. Natasha and I both spent a minute in the cold room to escape the heat. Many studies require tracking locations of animals over time. We saw a variety of tracking devices, for animals big and small. They were more compact than some of the earliest generation devices we had seen at the museum.
Why are these tracking collars in a tree? They are solar-powered!
I had never really thought about how difficult it would be to transport a tranquilized elephant to a facility where it could get extended care. Michele showed us the trailers used by the Veterinary Wildlife Services for this purpose. When an elephant wakes up in the shipping container-sized “recovery room,” its instincts tell it to back out of the space. The trailer in which the animal can be transported is helpfully positioned at the “exit.”
One is a black rhino skull, and the other is a white rhino skull. Can you tell which is which?
I was glad that the facility has two rhino skulls on display to understand the difference between black rhinos and white rhinos (they are different species). I hadn’t realized that white rhinos are gregarious (they like to hang out with their own kind), while the smaller black rhinos tend to be more solitary. Black rhinos have pointed lips, able to strip leaves and fruits from branches. The larger white rhino has developed wider lips that are better for grazing. Sadly, the numbers of black rhinos worldwide have now fallen below 10,000. Perhaps three times as many white rhinos now remain.
Michele spoke about the condition in which rhinos are found when poachers attack the animals. She showed us a collection of skulls that illustrated their activities. She has seen cases in which the animal was still alive at the time the horn was sawn off, for example when poachers have repeatedly cut at the animal’s backs to paralyze them. Some conservation sites now surgically remove the horns of rhinos to enable the animals to live with less fear of poaching. I am proud that my friend Michele is at the forefront of saving the rhino for future generations!
The rhinos are sometimes alive as the poachers remove their horns.
After our visit, Michele took us on a tour of the staff village. Skukuza is home to many other administrative and conservation services. Michele estimates that the village now features more than 200 houses. We saw many facilities that make this seem like any other town: a church, a swimming pool, and basketball courts. What really surprised me was when Michele revealed a nine-hole golf course! Because it is unfenced, impala, hippos, and even crocodiles wander onto the course. Apparently even lions have been seen wandering in some parts of the town. Of course, not just anybody can decide to move to Skukuza staff village Michele explained that house allotment is keyed to the seniority of the role a new employee will play in the organization. If SANParks is not your employer, you are not allowed to live in the village.
Dinner with the monkeys, redux
At dinner, we noticed a heavy accumulation of vervet monkeys at a neighboring rondavel. When we investigated, we saw that they had left coolers and some supplies for dinner in their outdoor cooking area. The monkeys had grabbed the packet of macaroni and were greedily gobbling it up. From time to time two of them would argue over a handful and raise an unholy yell.
For the rest of the cooking time, I was on monkey duty. If one of the troop started sniffing in our direction, I would do my best body-builder pose and growl. None of them decided to pierce my bluff by charging!
Morning Game Drive: December 21, 2019
The sun was not yet peeking above the horizon at the Sabie.
Waking for a 3:15 AM alarm was not easy, even if we were excited about our morning game drive from Skukuza Rest Camp. We had been told to rally at the parking lot at 3:45 AM (for a 4:00 AM departure), though, so we pried ourselves from the pillows. Would we see some of the signature cats of the park, this far south?
Our 24-person truck managed to exit the Skukuza gates roughly on time, though it had to scoot into the oncoming traffic lane to bypass all the personal cars hoping to exit the camp as soon as the gates opened for everyone. Right away, though, we could tell something was wrong. The lights operated by the two people in the back of the truck were distinctly yellow and quite dim, not the bluish halogens of our Satara night drive. We had only traveled a mile before the high side lights at the front of the truck failed. Our driver seemed unsure what to do at first, but then she turned us around to return to Skukuza for a different truck. The joys of unloading, reloading, and navigating around an even longer queue of personal cars consumed more time (especially since we had an incoming SANParks Jeep). We were back on the road by 4:30 AM.
This spotted hyena was in considerably better shape than that one we saw at Satara.
Since the summer solstice is tomorrow, we were barely out of the camp in time for sunrise. Our truck had a fair number of visitors from Spain, and some of them were “twitchers,” bird watchers. Our first stop of the day, in fact, was for a pair of Marabou storks, perched in a tree. Soon thereafter, we stopped for a Southern yellow-billed hornbill. I was really proud of Natasha for catching a spotted hyena (this time in good health) at the side of the road. A warthog seemed a bit shy, hiding behind some tall grass clumps.
We passed a fair number of gullies and creeks and rivers without seeing much of notice. Rather suddenly, a fellow in the back sang out for a stop. He claimed to have seen a big cat! He called for the driver to back up for a dozen meters, and he pointed to a oddly-colored patch in the grass. I automatically said to myself, “false positive,” but then the patch moved slightly. That brownish-gold patch had spots! For all the time I had spent watching likely tree limbs for a sprawled leopard, I had no sightings. This guy had spotted one lying in tall grass! I breathed a sigh of relief that I had brought my telephoto lens and that the sun was up. My best shot of the cat came at ISO1600. I don’t imagine the cell phone images turned out so well.
This leopard was watching us as we watched him or her.Leopards have rosettes rather than spots.
After that, our truck of tourists was a lot happier. We’d scratched off the most challenging member of the “Big 5!” We soon came to a river, and again someone called us to a halt. This time, they claimed to have seen a lion! The beast was quite far from the truck, and once I cranked the telephoto to maximum magnification, I was surprised to see a male adult lion with a full mane. The other tourists definitely had their eyes sharpened for this tour.
Thank you, Mr. Lion, for lying down in a spot with a clear view from the bridge!
While we and other vehicles pulled aside on the bridge for a better look at the lion, a number of other creatures had come to the bridge to stake their claims. Around seven baboons had infiltrated the group of cars, and some of them were rather big. I enjoyed watching one picking nits off another, but some of the louder hoots barked by the big ones were a bit scary. It wouldn’t be much effort for a baboon to climb into the open-sided truck with us. As we slowly navigated away to the far side of the bridge, Natasha and others spotted a hippopotamus blowing bubbles and frolicking in a side-channel of the river. He didn’t surface very much, so our photos just look like a particularly green bit of the river.
The baboons thought the lion watchers were very entertaining, except for one who didn’t get enough sleep.
For the rest of the tour, we didn’t have many notable stops (though we did observe some kudu). I saw that many of us were battling to stay awake, and that’s not a recipe for alert animal-watching. I had a bit of hallucination about the tea I would soon be drinking! The sun was soon high enough for normal daylight photography, but the animals had seemingly taken the cue to nestle down for a nice nap. We returned to the camp with a general sense of contentment.
Saying Goodbye in Style
This pied kingfisher’s quest for dinner kept us entertained for a half hour.
We spent much of the rest of the day in a combination of napping, reading novels, munching, and other distractions from the high outdoor temperatures. As we came to the close of the day, though, we opted to have a celebratory dinner. Tomorrow is the solstice, after all! Natasha put on a pretty dress, and I donned one of the two polo shirts I brought. As we stepped onto the main pedestrian walkway, we saw a momma warthog and two of her piglets just a few feet away. We had noticed them in the camp yesterday, as well. We turned in the other direction. Our steaks were excellent, and the staff took good care of Natasha’s dietary needs.
We took a farewell promenade to the riverside. I made what is probably my last false positive call for a crocodile in the shallows. Tomorrow we will take our leave of the park by the Malelane Gate and then jet along the N4 to Witbank / eMalahleni. It’s our first big step toward home!
Rolling Out: December 22, 2019
This African spurred tortoise has had a rough time of it.This chameleon stood out rather well against the road surface!
On our summer solstice, Natasha and I made our farewells to Kruger National Park. We drove essentially south from the Skukuza Rest Camp to leave the park via the Malelane Gate (a great way to connect with the N4 highway). The road led past some of the rockiest terrain of the park. Surprisingly, in only 90 minutes or so, we crossed paths with a large number of animals. Two of Natasha’s favorites were represented when we found a small African spurred tortoise crossing the road and then a giraffe. Ever since Satara, I had been looking in tree forks for a lazing leopard. Close by the exit, we saw just that! With his tail waving back and forth in the breeze, the leopard was standing on a branch. Perhaps our photo will be too back-lit for detail, but to see him at all was a serious payoff! Having seen very few elephants since departing Satara, we were delighted to encounter two young elephants blithely galloping across the road. What an exit!
Leopards thrive in trees. See this one’s tail hanging down?
An index to this series can be found at the first post.
December 11, 2019
To say Natasha is enthralled by archaeology is a little like saying I am fond of cookies. We simply could not come to Gauteng Province without visiting its World Heritage site, the Cradle of Humankind (Sterkfontein Caves and Maropeng Visitor Centre).
Everybody needs to try masala dosa for breakfast at least once.
Since the caves are at least an hour drive from city center, Natasha and I spent a little time on foot to let the commuter traffic clear. We wandered just east of our hotel to the Ruchi South and North Indian Restaurant for breakfast. Natasha and I sat down to masala dosas, and I enjoyed a cup of masala tea, as well. The dosas were massive and oh so tasty. We ordered another pair of dosas in transportable form for lunch.
It’s young, vigorous Gandhi!
From there, we walked up to Gandhi Square (named as the location where Mohandas K. Gandhi first established his law office). We saluted his statue. On the way back, I photographed Natasha with the replica of the golden rhino along Main Street. With that, we were ready to make our drive out to Sterkfontein Caves!
Using Google Maps on your phone for navigating an unfamiliar city is a good thing and a bad thing. This morning, it was able to untangle a set of unexpected turns into a course back to the Calabash Stadium and then onto the M47. The road was heavily used, and we again encountered areas where the traffic lights were blinking red or powered down for a major intersections. If the power grid is turned off, what can one do? After a while, though, we were out in the countryside, and navigating to the caves was pretty easy.
Sterkfontein Caves and Museum
I had recommended that we visit the caves first because they were definitely on Natasha’s bucket list, and I remembered the accompanying exhibits as being a very solid all-around on the current state of anthropology. I visited the site for the first time in August of 2018, and I hadn’t realized the place would look so very different in December (while Cape Town gets winter rains, Gauteng Province gets summer rains). As our group set out for the cave in hair nets and safety helmets, I suddenly realized that the rains of the last few days had released hordes of biting ants from their anthills, and Natasha had worn sandals after I described it as an easy walk. She was stepping very nimbly to reach the cave entrance.
The modern entrance features stairs. In prehistoric times, the most frequent entrance was via a fall through a hidden crevasse.
If you have no interest in man’s origins, you might be forgiven for thinking the caves hold hominid remains because they were cave-men. The truth is that human ancestors weren’t very keen on living underground at any stage. Sterkfontein caves, made of limestone much like the Cango Caves at Oudtshoorn, contain hominid and other animal remains because a great many vertical shafts were open to the surface in areas surrounded with brush and trees. People fell into these holes, and they couldn’t get out again.
One does not simply walk into Little Foot’s resting place…
Arguably, the two greatest hits from the Sterkfontein Caves are “Mrs. Ples” and “Little Foot.” The former, a nearly complete Australopithecus africanus skull, was discovered in 1947 by Robert Boom and John T. Robinson. Little Foot, on the other hand, is a nearly complete skeleton of an early Australopithecus (potentially a new species), dating from 3.67 millions years ago! Little Foot might have been missed altogether except that Prof. Ron Clarke was digging through a box of “animal bones” and recognized that these fragments were from a primate rather than another animal. They returned to the grotto that had produced the animal bones and were able to find other bones embedded in breccia. It would be unfair of me not to mention that the World Heritage Site spans three different fossil-producing sites in South Africa. The Taung Child fossil was found at another site, this time in the Northwest Province. This skull fossil was remarkable for enabling a cast of the child’s brain, teaching us a lot about the development of hominids at nearly three million years ago.
Our walk through the Sterkfontein Caves was largely uneventful, though I should have provided better guidance on footwear. At least sneakers would offer a better grip on some of the downslopes (covered with rubber matting). I’d forgotten that some crouching is required for navigating a low gallery. A small child with our group started out with fears of the dark, but by the end he was marching triumphantly through the path. Nobody seemed terribly phased by the story of three Wits students who tried to map the underground lake; one was left by himself for a while and wandered into unexplored areas, eventually dying.
Dripping water from the recent rainfall created some pretty views inside the cave.
If you are accustomed to beautiful grottoes like the Cango Caves, you might feel disappointed by Sterkfontein. The cave was well on its way to complete denuding via lime mining when its importance for human evolution was discovered. Our guide, Romeo, gamely pointed out “elephant rock,” a substantial flowstone that looks a little like a massive trunk below a big pair of ears. I found it more interesting to look up, since the vertical holes into the cave are still in place, and rain water continued to filter and drip down into the cave from above.
Profs. Tobias and Broom are both honored with statues at the exit.
As we exited the cave, we paused with two great explorers of the caves, and Natasha surprised me by saying she had met Prof. Tobias in her undergraduate anthropology courses! He was apparently a very creative thinker, to the extent that he was always ready to talk about the next idea before finishing his prior sentence. We continued on the longer return path to see the excavations that had produced Mrs. Ples. I kept an eye on the path because the area is apparently a great favorite of snakes. The ants continued to be very aggressive, and Natasha felt a bite or two on her leg. We accelerated, hopping from each stepping stone to the next with alacrity. When we reached the sidewalk, we came to a full run to return to the visitors’ center.
Maropeng Visitor’s Centre
The Maropeng Visitors Centre is essentially a children’s science museum.
We spent the next fifteen minutes driving to Maropeng, the standalone museum for the Cradle of Humankind. The building is a really cool ecologically smart design, and in December it’s covered in green grass rather than the yellow straw one might see in August. We entered the exhibit and curved down the spiral of Earth’s history, from modern times down to the Vredefort Dome impact, the origins of life, and the formation of the Earth!
At the bottom, we heard the sound of water running, and we entered a room to be told to seat ourselves in a little round boat. For the next few minutes, our boat bumped down a watery channel. At first we were traveling in a tube of blue light, and then we passed into a frozen tunnel. We flinched when we thought we’d pass under a waterfall, accompanied by the sound of thunder! Soon, though, we were passing through a fiery region. When we hopped out of the boat on the other end, the docent directed us into a vortex tunnel, but I knew from my prior visit that my vertigo would act up very badly in there. Natasha and I both opted to bypass that part. [We learned from the website that the passage was intended to show the evolving biome of the Cradle of Humankind area.]
Plenty of levers and buttons!
From there, Maropeng essentially becomes a well-executed children’s science museum. Kids can see full-size models of what we think Australopithecus species looked like. Certainly they learn a lot about geology and the Earth’s history. They can answer science questions by pressing buttons. They can pass whispered messages through a tube phone. It’s pretty cool! The sad thing is that there were very, very few people visiting the facility during our time there. I am sure that the place absolutely hums with life when a school group comes through, though.
If the union of biology and chemistry is biochemistry, does this count as biogeology?
The museum posed some challenging questions at the end, such as what kind of world will we leave ourselves if overpopulation continues its march forward or if humanity continues developing ever-better weapons to kill each other. I was a bit mystified by this question: “What is the Human Genome Project?” They’d answered, “The United States spends about 7.5 times what South Africa does on health per person.” How exactly do these two statements relate to each other?
Natasha and I exited the museum into a rain showers. We took shelter for a moment and the pace seemed to slacken. We hoofed it for the parking lot. The path veered in the direction of the gift shops rather than the parking lots, so we hustled across a muddy meadow to reach the car that much faster. We paused in the car to eat our second masala dosas of the day, and then came a critical question. The time was 14:00. Should we retire back to the hotel, or should we try for the Mapungubwe Collection museum at the University of Pretoria (we believed it closed at 16:00)? Each destination was about an hour away. Natasha acquiesced in a run to Pretoria. I started the car.
A failed side quest
Our entry to Pretoria was pretty smooth. I was really quite surprised that the Voortrekker Monument is so large (and so westerly) that one can see it before essentially anything else in the city. We pressed ahead to the university campus, though, and soon we were safely ensconced in a parking structure. The security guards were able to give us enough information that we could find the old arts building that holds the mini-museum. Unfortunately, the security at that building were able to inform us that the Mapungubwe Collection is entirely inaccessible over the holidays; whether or not Google is showing open hours, it won’t reopen until January! Having just set a Dave speed record in reaching the campus, I was crestfallen. [Edit: museum curator Dr. Tiley let me know that the prominent gold artworks from the collection are now on permanent exhibition at the Javett UP Art Centre, which is open during the holidays.]
We believe this building on the U-Pretoria campus houses the Mapungubwe Collection.
Since we were in Pretoria, why not try for some other tourism goals? I announced my interest in seeing the Union Buildings, the center of South Africa’s administrative branch of government. Natasha was quite indifferent, wondering why anyone would care to see the government offices. I argued that the buildings were really pretty and historic, and wouldn’t she want to see the White House if she were in Washington, D.C.? NO??!! Why not? She agreed to come along to the buildings since they were only ten minutes away.
The Union Buildings
It’s a bit challenging to photograph the extremely wide Union Buildings complex from the drive below it!
Oddly, one can drive right up to the Union Buildings and park right at the front wall even at the start of the holiday season. In fact, the very first parking space was mine for the taking. We exited, and I gawped at the lovely facade. Granted, I couldn’t walk right up to the historic buildings but rather to the wall below them. We didn’t try to enter them through security. I just wanted some photos of the Herbert Baker-designed structure. It’s intended to commemorate the conclusion of the Anglo-Boer War (sometimes called the South African War), when the Boer Republics and British colonies (each represented by a tower) joined to form the Union of South Africa in 1910. J.M. Claassen had quite a lot to say about what this design meant in Herbert Baker’s evolution as an architect.
I felt bigger while standing next to this giant.
I got a little giddy when I realized we’d found the world’s largest statue of Nelson Mandela (cast in Cape Town). It stands on a landing in the gardens below the Union Buildings. Natasha had decided she rather liked the gardens, even if the buildings weren’t her thing. I was glad she was willing to join me in descending the flights of stairs to see the nine meter statue up close. Nelson was really popular with visitors, and group after group came up to his feet for a photograph. I noticed that people had covered both his feet in a blanket of flowers. It’s a lovely tribute to one of South Africa’s most iconic world figures!
The Union Buildings afford a great view of downtown Pretoria.
Google Maps told us that we were an hour from our hotel, but we forgave it for the lies. It led us on a merry chase down R21 Albertina Sisulu Freeway, which was reasonably clear. When I heard the car’s “ping,” I knew I needed to stop for gas, and Maps was able to find one for us just six minutes ahead. Some of the interchanges that it had us perform were very problematic. From the R21, we moved to the westbound N12 and then west on Kraft Road. When Kraft became Pretoria Road, we found ourselves driving past the Primrose fire station, and the informal shops were not tony. We had a lot of problems getting from Pretoria Road to Main Reef Road. After that we were almost home free! As we approached the downtown, though, Google Maps went into a glitchy recalculating loop until Natasha was able to reset it. It found us an exit very close to our hotel, and we were in the absurdly narrow passage to the garage moments later.
An index to this series can be found at the first post.
December 9, 2019
After a night of powerful electrical storms, waking up a 5:30 AM seemed a bit early. Then again, the sun rises just after 5:00 AM this close to the solstice! Natasha and I hit the road for Johannesburg. On the way, though, we stopped for a hike at a most unusual site.
We decided to stop for gas at Winburg. I didn’t realize that the gas station was 5 km away from the N1. Our spur road, though, let us see the top of a monument built to remember the Great Trek; the main monument is one we’re likely to see in the next few days. At Kroonstad, we veered left from the N1 to follow the R721. We saw some long-tailed widowbirds playing near the road. I wondered how a bird could fly, dragging around a drogue parachute all the time!
A drive time of 5 hours left us some tourism time!
Before too much time had passed, we came to the town of Vredefort, which lends its name to a geological feature that dominates the area, the Vredefort Dome. We navigated just a bit further to cross the Vaal River at Parys, thus entering the Northwest Province. We had reached Otters’ Haunt, the home of Graeme and Karen Addison, our guides for the day. Their two border collies gave us an enthusiastic welcome.
Graeme and Karen Addison offer a lot of skill to help explain the Vredefort Dome.
The Vredefort Dome was inscribed as a World Heritage Site in 2005. It represents the largest and oldest meteorite impact structure we have detected on Earth. Some readers may have visited Meteor Crater in Arizona; it’s 1.2 km across and 49,000 years old. Others may have seen Crater Lake in Oregon. While it’s larger, at 9.7 km across, it’s actually a collapsed volcano and not the product of a meteorite strike at all! By comparison, the meteorite that ended the age of the dinosaurs (65 million years ago) struck the earth at the Yucatan Peninsula in Mexico, creating a crater 150 km across. Vredefort Dome was formed by a meteorite impact southwest of Johannesburg, producing a crater 300 km across (four times the area of the one at the Yucatan), but the event took place just over 2000 000 000 years ago; that’s approximately 45% the age of the Earth itself!
This geological map is similar to one shown by the Addisons, but this is available online due to expired copyright. The irregular line across the dome is the Vaal River.
What happens when a meteorite the size of Table Mountain hits the earth at astronomical speed? The short version is that even bedrock can become liquid or even a gas if it absorbs enough energy. The crust at Vredefort was a layer of granite covered by three additional layers of sedimentary rock; one of these, the Witwatersrand Supergroup, contained substantial gold. At impact, many tons of rock were instantly vaporized, and when the superheated rock blasted up and out of the crater, it formed not only the immediate crater walls (once as tall as Everest) but also ripples up to 300 km away. The Witwatersrand layer was so deformed that some of the layer was exposed on the surface while other parts were thrust many kilometers below the surface; these are the basis of South Africa’s gold mining operations today.
This pseudotachylite seam was once melted obsidian in which other rocks were rounded and embedded as it cooled.
After a really informative video featuring geologists from nearby University of the Northwest, Karen took us on a local tour including two hikes, one in a nearby quarry and one to a scenic overlook that showed the portion of the innermost ring of the Vredefort Structure arcing around its northwest side. At the quarry, we saw huge seams of pseudotachylite, areas where molten obsidian quickly cooled to form glass, often with rounded stones of other kinds embedded in the obsidian. The granite of this area frequently comes with pink and black regions mixed together. The blocks that are sliced elsewhere are really massive. We were happy to learn that the cores used to cut a block of granite away from the rest of the rock formation left holes could be played like musical instruments. Karen also asked us if we recognized a purplish bush on the ground as a “Bankruptcy Bush.” She pointed to a left area of a pasture and noted that overgrazing had resulted in a shift from grass to the purple bushes, while the right area hadn’t been exposed to so many livestock and still showed grass everywhere.
This black vein is also pseudotachylite. This menhir appears at the entrance of Stonhenge in Africa River Lodge.
Our hike up the hill at Kopjeskraal Country Lodge would have gone better if I hadn’t messed up my toe a trio of weeks before the trip. I consistently lagged behind as we climbed the ridge. Natasha was delighted when we reached our first destination, a pair of rock rings that had likely been kraals where Tswana people kept animals from 300-400 years ago. Natasha pointed out a fringe of thick, interlocked bushes. Karen said these “puzzle bushes” are still used today for forming defensive barriers in South African yards. As we climbed further, we found a meadow where cattle were having a nice nap. Two wild warthogs ran away as we approached. At one point, we were subjected to warning glares from a cow keeping watch over a calf who had decided to nap on our route. We encountered all kinds of plants along the route, including something from the nightshade family (perhaps wild aubergines?). Near the top, we were able to take in a magnificent view toward the Vredefort dome, taking in the Vaal River, an orchard, and the quarry we had seen just a couple of hours before (photo appearing at the top of this post). On the other face of the ridge, we could see the “bergland,” ripples of other ridges lying further away from the impact. It was very tangible evidence than an event two billion years ago could shape today’s world.
Looking from the top of the first ridge away from the Vredefort Dome, we see an echoing ridge not far away.These “dinner plates” reveal that the four original layers of rock have been inverted in this area due to the titanic forces of the impact.
With that lovely reminder, Natasha and I continued to the Northeast to reach Johannesburg. However sleepy I was from driving, I was wired and on the edge of my seat as we passed across the highways of Johannesburg. A large truck tailgated me at high speed and swerved, barely missing me, when the car in front of me slammed on its brakes. Another car jammed itself into the gap formed in front of me, forcing another pump of the brake pedal. I am afraid I was in a rather poisonous mood by the time we reached the hotel!
An index to this series appears in the header of the first post.
September 20, 2019
A little less than four decades ago, my father took me to a Kansas City airfield for a show unlike any I had ever seen before. I saw grown-ups grinning like little kids, directing their model airplanes by remote control to fly loops and rolls! When I saw that the Cango Flying Club was organizing the 50th anniversary Oudtshoorn Scale RC event during my week off work, I knew I had to attend.
Many scales, and many eras
If you have never been to such a show, you might imagine a bunch of plastic airframes propelled by little electric motors. As I’ll describe, though, the types of planes and the engines that powered them were incredibly diverse. What distinguishes this airshow is its emphasis on scale models. For a scale airplane to qualify for the event, it needed to represent a real airplane that flies today or back in history. Every era of flight was represented, from the birth of flight at the start of the 20th century to contemporary jet fighters!
Perhaps the most dramatic example for me was a model of the Santos-Dumont Demoiselle (“Damselfly”). The real airplane first took flight in 1907 in France. Mark and Roux, representing the Cape Radio Flyers and the Stellenbosch Model Aircraft Academy, were piloting a Demoiselle in ovals around the Oudtshoorn Aerodrome. The other four planes in air were tearing around in acrobatics, but the Demoiselle took a more deliberate pace. Its slow speed made me hold my breath every time it reversed course. I decided to record a little video of the scrappy airplane; it was moving slowly enough that my camera could focus on it! Rather suddenly, though, the plane seemed to make an erratic turn, and then its nose pitched down. I imagined rather than heard a sick crunch as it smacked the dirt beside the runway and shattered to pieces. I felt terrible for its crew.
The remains of the damselfly. I am sure it will take the skies once more!
Real pride of place, however, must be given to the World War I-era Gotha G.II, a heavy bomber employed by the Imperial German Air Service (the Luftwaffe didn’t exist until 1935). The biplane features two wing-mounted propeller engines and a central fuselage for the pilot and gunner. I found myself wondering if this were the type of plane stolen by Indiana Jones in The Last Crusade! The enormous plane (perhaps a 1:3 scale model?) was towed by its pilots to the rear of the airfield for its brief flight. It seemed everybody was watching as they spun up its engines. It slowly lumbered into the air, and everyone applauded. It was only in the sky for a couple of minutes before it was navigated to a careful landing. The Pilot’s Post captured an amazing photograph of the plane in flight.
Just how would one transport such a huge plane?
I had interesting chats with Andries of the Bloem Radio Aero Team and Daniel of Port Elizabeth Radio Flyers. They explained that RC flight has been swamped by newcomers purchasing ARF (“Almost Ready to Fly”) kits. The artistry of building a scale model airplane from hundreds of parts takes considerably more time and energy. Because this airshow was limited to scale models, we were really seeing the products of months of craft. Electric motors are hardly the limit of today’s planes, though they are quite popular for reliability and cost. Plenty of airplanes at the show used two-stroke engines burning methanol, while others featured four-stroke engines burning unleaded fuel. One plane featured a turboprop, quite a technically complex mechanism to fit into a small space!
Oddly enough, South African companies produce components for the Eurofighter Typhoon.
As someone who grew up making model airplanes of military jets, though, I felt an incredible thrill to see scale model jets taking to the skies! My personal favorite was a model of a Eurofighter, dressed in South African colors. Werner previously flew with the Tygerberg Model Flying Club. The group apparently limited its activities to propeller-powered planes, though, so he has been flying solo in recent years. I also had my eye on a nearby model of an F-15, but I didn’t get to see it in motion.
The F-15 first flew in 1972, the year my brother was born.
I watched in awe as planes completed Immelmann turns, snap rolls and many maneuvers one could only do in an RC plane with more energy to spare than the real thing. The air marshals gamely kept limits on the total number of planes in the sky (and kept nosy bloggers behind the barrier separating pilots from civilians). I felt my head getting a bit warm, despite my hiking hat, so I paused for a blue slushy. Oh, life was very good!
In the evening, I attended a special indoor event for the Oudtshoorn Scale RC. The big boys had their fun in the morning, but the smaller aircraft, ranging from rubber-band powered planes up to electrical “foamies,” had a chance to fly inside the De Jagers Sports Complex. The cardinal event was the balloon race. All around the enclosed gymnasium, balloons were tied to crepe paper, with a chocolate bar tied to the other end. Whichever pilot popped the balloon could lay claim to the chocolate bar. Some of the balloons, however, were placed within PVC pipe squares or even under a folding table.
Two “foamies” attempt to destroy the remaining balloon.
Naturally, this event lent itself to younger pilots. One of their favorite tactics was to direct their foam airplanes into hovers, with the planes hanging down from their whining, madly-spinning propellers. That thrust-to-weight ratio is not typical of private airplanes!
Yes, you can power flight with a rubber band.
I was fascinated with the diversity of aircraft on display in the windless indoor environment. When I think “drone,” I automatically think “quad-copter.” A company called “E-flite,” among others, has been making very lightweight RC airplanes that are designed for indoor use. I must resist my buying urge! I sat next to Raffaele and Karin and their son; they had come from the Helderberg Radio Flyers near Somerset West to see the show. Their little boy was so excited; when he saw some foam gliders making an appearance, he begged his father to buy one. His dad replied that they would build one together. I rather suspect his son will someday be a young man attending the 70th anniversary of this event!
I am very glad that I was able to attend this 50th anniversary event for the scale model airplane community. I really had no idea that so many flying clubs surround me here in the Western Cape. If you are interested in this hobby, you might want to check in with the South African Model Aircraft Association to find a group near you!
An index to this series appears in the header of the first post.
As a rule, I try to avoid places that are surrounded for miles in every direction by roadside marketing billboards. Having been drawn to Safari Ostrich Farm to see its farmhouse Feather Palace, though, I knew I needed to take the tractor tour. I paid my R146 (around $10 USD) and waited in a shady spot on the bench. Conveniently, the site offers an extensive gift shop, a sit-down restaurant, and a large cafeteria to help one pass the time. Soon others began joining me on the bench for our 11AM tour. I was pleased that I could differentiate the accent from Great Britain from the accent of South Africa (don’t judge– I’m an American!).
Our group appeared to be only five people, and the site appointed Picasso as our tour leader. He seemed very young, and he didn’t have the tour guide badge in the colors of the South African flag, but Picasso handled himself well as he still pointed our little group into the start of the tour. It began a bit damply as we were all walked over a sponge filled with disinfectant to protect the youngest birds we would see. We entered a room displaying some basics on the birds, including a replica of an early ostrich incubator model. The “Eclipse” triggered a revolution in the ostrich industry, back when it was invented by Arthur Douglass in 1869. Shooting wild ostriches for their feathers was inhumane and wasteful, but controlling the birds from the moment the eggs were laid led to much more manageable animals. Picasso shared that ostrich chicks require several hours to break out of the eggs, kicking with their toenails to shatter the 2mm-thick shells.
Ostrich feathers remain the height of fashion.
Picasso was rather suddenly taken from us. A group of approximately ten Brazillians had been a bit tardy to come to the tour start site, so Picasso returned to walk them over to us. We peered around the chamber and discovered a booth with natty leather hats and ostrich feather boas. The Brits and I wasted no time acquiring some photos in these high fashions.
When Picasso returned with the large group, he found us spread all over the room, but soon he marshaled us into a coherent, listening audience. I was grateful for a little discussion on the niche the ostrich fits among the Ratitae: flightless birds. Yes, the ostrich is the largest flightless bird today, but a couple thousand years ago, that honor would instead have gone to the elephant bird, found on Madagascar. I liked the exhibit Picasso showed us that compared the thick sternum bone of the ostrich to its tiny brain (you could probably fit three or four brains into one ostrich egg). The emu, a significantly smaller flightless bird in Australia, produces an egg of nearly the same diameter as the ostrich.
The breast bone is a key factor differentiating flightless birds from others; it has no keel for wing muscle attachment.
As we came outside, it was time for Picasso to demonstrate the incredible strength of ostrich eggs. We were invited to stand atop a small clutch of eggs. He noted that the eggs could likely withstand the force of a person massing 220 kg (~485 pounds) atop them. Nobody in our group was even close.
The female African ostrich is gray, while the male is black-and-white.
From there, we had the opportunity to meet the birds up close. We learned that the adult male and female birds can be easily distinguished by coloration. The black and white color pattern (along with a frequently dusty tail) is the male bird, while the gray pattern distinguishes the female. The adults we saw in this first enclosure were around twenty years of age, but they can live just as long as humans can! The birds were clearly not intimidated by us. Both males and females snapped with their beaks at the top wires of the fence. We had all received the warning that an ostrich will snap up anything shiny it sees. I kept my distance. Several people, though, tried their hand at feeding the birds.
The jerking lunges for the food in mid-air left me sure I should keep my distance.
Oudtshoorn was ideal for the ostrich industry in two particulars: 1) its temperature led to rapid plumage replacement (ranchers could pluck adult birds every eight months), and 2) the area’s soil is rich in lime, making it ideal for growing lucerne (Americans would say alfalfa). The lucerne is milled into pellets for the birds to eat. The guests at the farm could scoop up some pellets and toss them in the direction of the ostrich, which would strike at the pellets to gobble them mid-air. It looked downright threatening! Picasso built their fearsome reputation by noting that the middle toenail for an adult ostrich can grow to seven centimeters (3 inches). Yes, an ostrich can disembowel a lion with a lucky kick. The toe claw also plays an important role in traction as the birds maneuver at high speed.
Emus are from an entirely different continent than ostriches.
The Safari Ostrich farm is also home to emus, but these animals are only for show; they are not farmed for feathers, leather, or meat like the ostriches (though some enterprising farmers have grown them to produce emu oil!). The emu enclosure had just a few animals, and they seemed much less prone to intimidating the visitors. Picasso noted that the females were more aggressive than the males, a reversal of the ostrich split.
Nice trailer you have here. It would be a shame if something were to happen to it!
With that, we boarded the trailer for our tractor ride. It wasn’t a particularly long loop. I hadn’t anticipated that our trailer would be rolling among the birds. Those long necks allow for quite a lot of reach! Because the driver occasionally dumped a shovel of pellets on the ground, the birds were very interested in us. I and others reached out to touch their feathers when they were distracted.
These ostrich chicks were just adorable.
Seeing the five-day-old chicks was definitely a highlight for me. The light colored feathers on a dark background made them look like hedgehogs! I liked the cheetah racing stripes on their necks, too. The enclosure of individuals that were several months old was interesting, too. I hadn’t realized that determining the sex of the animals required them to age so much. The ranch had quite a range of ages all mixed together.
The scientific name for the ostrich is Struthio camelus. The displays had informed us that the farm featured subspecies of ostrich from three regions: South Africa, Zimbabwe (just northeast of South Africa) and Kenya. The Zimbabwean birds are even larger than the South African ones. As our trailer passed by, the male seemed to lose his temper with the female standing nearby. It was unnerving. South Africa invested serious effort into acquiring breeding birds of “double-fluff” plumage from the rest of Africa back in 1911, but since the ostrich farms have turned their attention to leather and meat, I suspect those lines have not continued to today.
Check out the leg muscles on both of these Zimbabwean ostriches!
The Kenyan birds seemed much more restrained. The male bird spread his wings wide, as though showing his toughness. I imagined my older brother ghosting a punch at me and taunting me, “you live in fear.”
The Kenyan ostrich brings out the gun-show.
With that, our ostrich adventure had come to a close. Having been this close to adult ostriches, I would only say I feel more intimidated by these birds than before! I will continue to look forward to my next ostrich burger.

























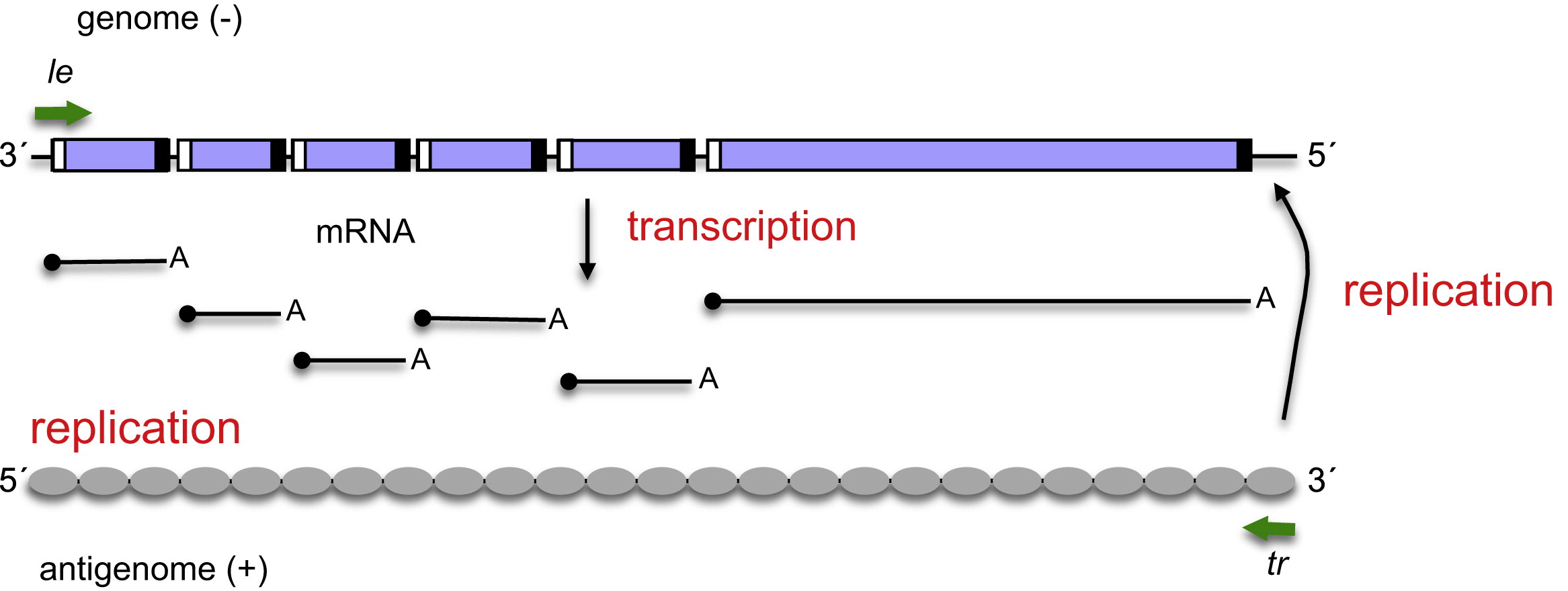


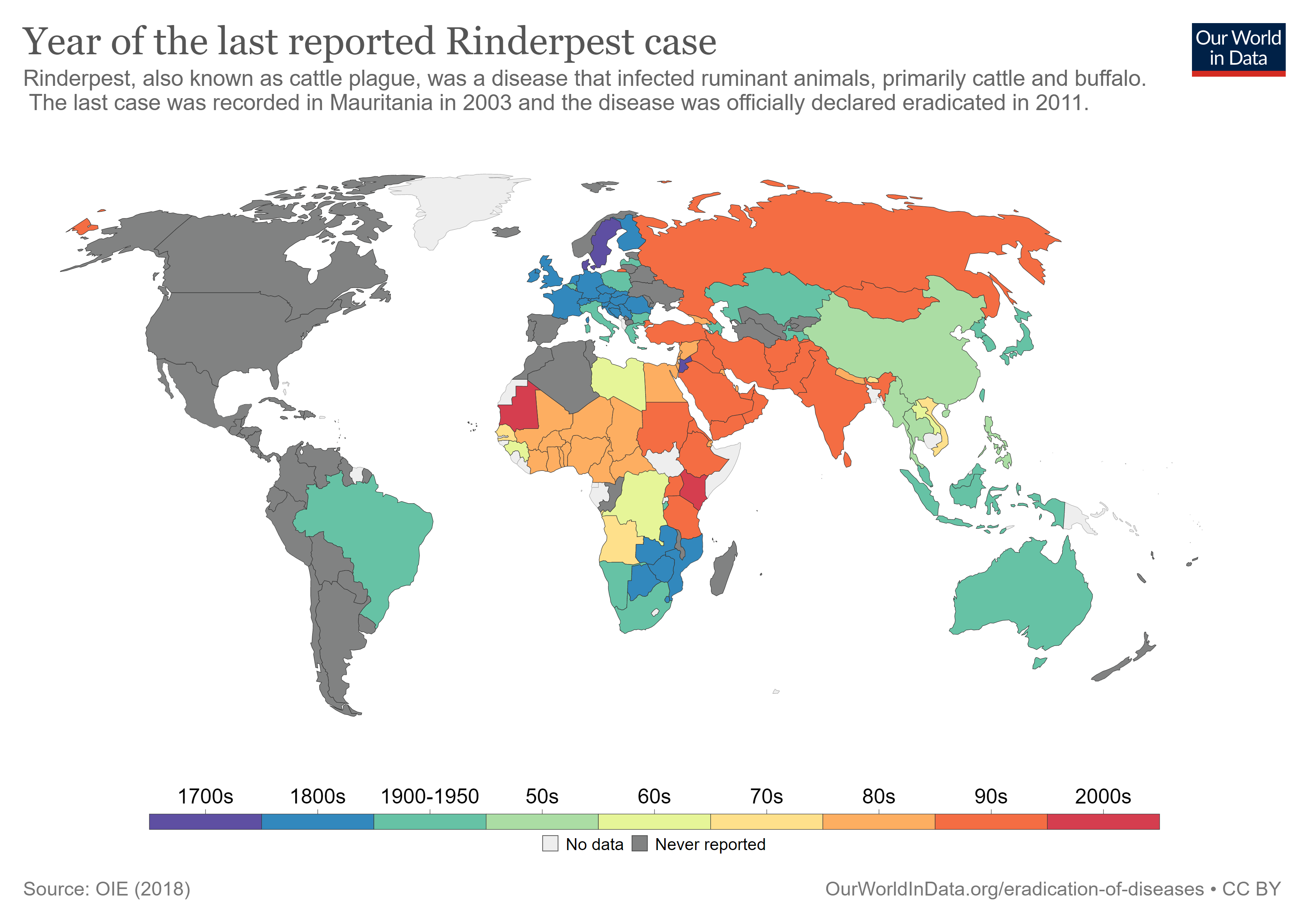







































































{kind=link}
{kind=link}
{kind=link}
{kind=link}